Representing Text (BoW & TF-IDF)
Subject: Natural language processing (VU-CSC 322)Introduction: Why Represent Text as Numbers?
Computers don’t understand words like humans do. They understand numbers, not language.
So before a machine can work with text (like analyzing WhatsApp chats, tweets, or student feedback), we must convert text into numbers. This process is called:
Text Vectorization (or Text Representation)
Example
Imagine asking a computer:
- “I love jollof rice”
- “I hate jollof rice”
To a human, these mean opposite things.
To a computer, both are just strings unless we convert them into numbers.
Another example: If you say “I love pizza”, the computer needs to turn that into something like [1, 1, 1] (counts of words).
Bag-of-Words (BoW)
Bag-of-Words is the simplest way to represent text. It counts how many times each word appears in a sentence, ignoring grammar and order.
Example
“I love jollof rice”
“I love fried rice”
“I hate burnt rice”
Step 1: Create Vocabulary
List all unique words:
[I, love, jollof, rice, fried, hate, burnt]
Step 2: Count Words

Key Idea
- Each sentence becomes a vector (list of numbers).
- Order of words does NOT matter.
Advantages
- It is very simple
- It is easy to understand and implement
Disadvantages
- Ignores meaning and word order
- Common words like “I” may dominate
TF-IDF (Term Frequency – Inverse Document Frequency)
TF-IDF improves BoW by giving importance to meaningful words and reducing the weight of common words.
Idea Behind TF-IDF
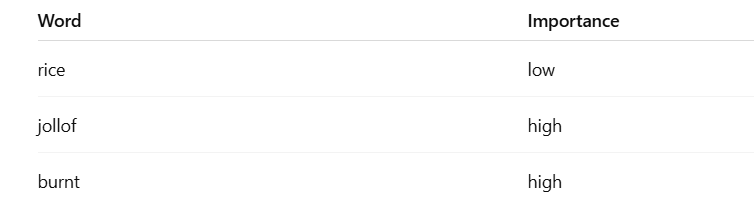
- Words like “rice” appear in all sentences less important
- Words like “jollof” or “burnt” more informative
Two Parts
1. Term Frequency (TF): kow often a word appears in a sentence. For example, in a classroom word like "student" is use frequently - (less useful)
2. Inverse Document Frequency (IDF): how rare the word is across all sentences. In a classroom word like "scholarship" is rarely used - (more meaningful)
Therefore In TF-IDF gives:
Important words have Higher weight
Common words have lower weight
4. Hands-on with Python (scikit-learn)
Step 1: Install Library
pip install scikit-learn
Step 2: Bag-of-Words Example
from sklearn.feature_extraction.text import CountVectorizer
sentences = [
"I love jollof rice",
"I love fried rice",
"I hate burnt rice"
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(sentences)
print(vectorizer.get_feature_names_out())
print(X.toarray())Output: BoW Matrix
['burnt' 'fried' 'hate' 'jollof' 'love' 'rice']
[[0 0 0 1 1 1]
[0 1 0 0 1 1]
[1 0 1 0 0 1]]
Step 3: TF-IDF Example
from sklearn.feature_extraction.text import TfidfVectorizer
sentences = [
"I love jollof rice",
"I love fried rice",
"I hate burnt rice"
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(sentences)
print(vectorizer.get_feature_names_out())
print(X.toarray())Output: TF-IDF Matrix
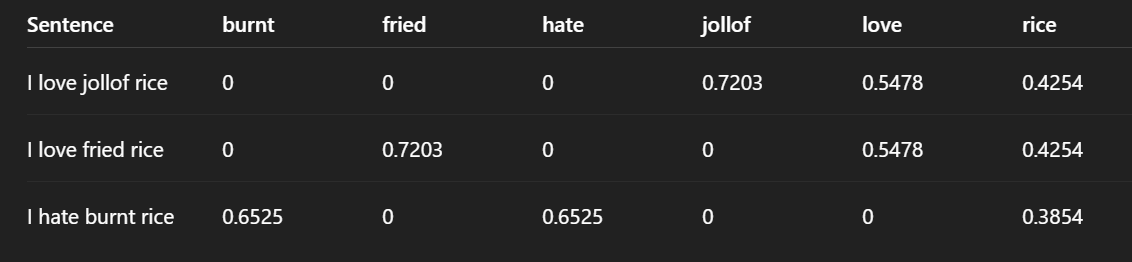
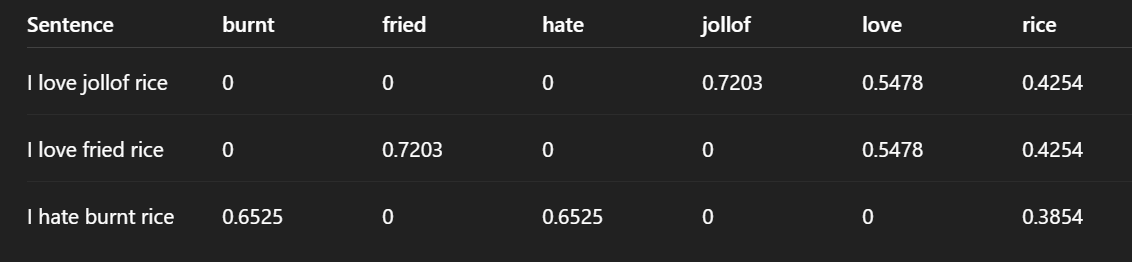
['burnt' 'fried' 'hate' 'jollof' 'love' 'rice']
[[0. 0. 0. 0.72033345 0.54783215 0.42544054]
[0. 0.72033345 0. 0. 0.54783215 0.42544054]
[0.65249088 0. 0.65249088 0. 0. 0.38537163]]
Observation
- Values are no longer just 0 and 1
- Important words have higher decimal values
These are all the unique words found across your sentences.
The vectorizer:
- Converts all text to lowercase
- Removes duplicates
- Sorts words alphabetically
- So each word becomes a column (feature) in the TF-IDF matrix.
Each row = one sentence, each column = one word.
Remember
a. High value → Important word in that sentence
b. Zero → Word does not appear in that sentence
Words unique to a sentence have higher scores
"jollof" → only in sentence 1 → 0.7203
"fried" → only in sentence 2 → 0.7203
"burnt", "hate" → only in sentence 3 → 0.6525
These words are very important because they distinguish the sentences.
Words shared across sentences have lower scores
"love" appears in sentence 1 and 2 → lower score (0.5478)
"rice" appears in ALL sentences → lowest score (~0.42–0.38)
This is because TF-IDF reduces importance of common words.
TF-IDF gives high scores to rare, meaningful words and low scores to common words.
5. Classroom Activity (Very Important)
Activity 1: Given the following sentences:
“I like Python programming”
“Python is difficult”
“I like coding”
- List vocabulary
- Create BoW table manually
Task
1. Collect 5–10 sentences (WhatsApp chats, tweets, or news headlines)
2. Clean the text
3. Convert to: Bag-of-Words AND TF-IDF
4. Compare results
Count Words

Intuition
Matrix 2
By: Vision University
Comments
No Comment yet!
Login to comment or ask question on this topic
Previous Topic Next Topic
- 1 Introduction to Natural language processing (NLP)
- 2 Text Preprocessing Basics
- 3 POS Tagging and NER
- 4 Representing Text (BoW & TF-IDF)
- 5 Introduction to Text Classification
- 6 Models in scikit-learn
- 7 Text Classification with Multiple Models